


Introduction
"Machine Learning with Golang?" you ask. Well, yes. Ever since I picked up Go, have been convinced that I could actually use the language for everything I want to get into. My primary language is Python, but I see Python a bit different from people.
Python is the BASIC of this era. It is the default go-to language for people just starting out, or people who don't want to do much important things in the computer world.
As a matter of fact, starting a project in any dynamic language (Python especially) is easy but as the project scales, it takes so much more effort continuing on that language. In contrary, a statically typed language allows you to easily add to the codebase as the project scales. Refer to the image below for clarity.
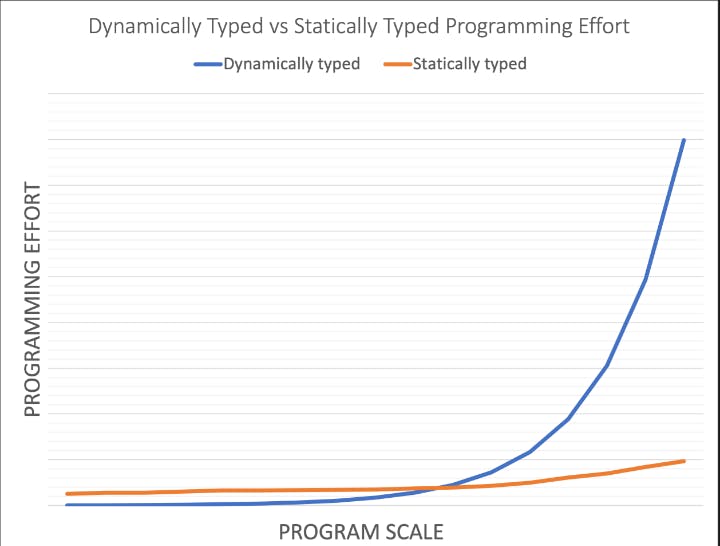
That said, I very much agree that Python is still a powerful, fast growing and modern language and has the most library support for data science.
Why I Ventured Into Machine Learning
Technically, I'm a software developer with a bias for Security and CloudOps. However, my educational career is pivoted around Artificial Intelligence and Robotics (AIR). Immediately I stated working part-time as a Robotics Engineer for DPN in late August of 2021, I knew it was time to delve into the AI space. As a result of this, my articles will be more focused on the robotics aspect of Machine Learning.
File Handling With Golang
Managing data in files is the very basic task in machine learning. When sensors collect data from the environment, they convert it into a .txt (or other extension) file for storage in a cloud-based or local server. In general ML, however, datasets can be found in .csv format and a machine learning engineer must be able to work with this.
Handling CSV Files
We can parse CSV files with Go while leveraging Go's explicit error handling technique to ensure that the data is properly organized as follows:
package main
import (
"os"
"log"
)
// Open the CSV
f, err := os.Open("myfile.csv")
if err != nil {
log.Fatal(err)
}
// Read CSV content
reader := csv.NewReader(f)
records, err := reader.ReadAll()
if err != nil {
log.Fatal(err)
}
As seen above, Go allows the machine learning engineer to maintain high data integrity while manipulating data files. Data Integrity is an aspect of the CIA security triad model which requires data to remain untampered through unwanted means.
Reading CSV Files
As mentioned earlier, CSV files are not used for storing big data. However, the Go ML Engineer must know how to perform basic CRUD operations on a CSV file.
Consider a CSV dataset named Startups.csv, which provides data on 250 highest valued startups for 2022. The dataset has 5 columns (Company, Valuation, Valuation_date, Industry, Country) and is pulled from Kaggle.
The Go ML Engineer can process the file as follows:
1. Open the CSV file and create a reader value
package main
import (
"encoding/csv"
"os"
"log"
)
//open Startups dataset file
file, err := os.Open("../folder/Startups.csv")
if err != nil {
log.Fatal(err)
}
defer file.Close()
// create new reader
reader := csv.NewReader(f)
2. Read the contents of the CSV file
The contents are read as [ ][ ] string and the rows must be configured to have variable number of fields by setting FieldsPerRecord negative:
reader.FieldsPerRecord = -1
// read all contents
rawCSVData, err := reader.ReadAll()
if err != nil {
log.Fatal(err)
}
Use the csv.Reader.Comma and csv.Reader.Comment fields to properly handle uniquely formatted CSV files such as those without commas, or with commented rows.
Creating Data frames from CSV files
To create Data frames, a third-party library has to be used. Importing the Dataframe library gives a dataframe package for filtering or selecting portions of a dataset.
package main
import (
"os"
"log"
"fmt"
"github.com/go-gota/gota/dataframe"
)
To create the dataframe, we open the Startups.csv file with os.Open() and then pass the returned pointer to the dataframe.ReadCSV() function:
file, err := os.Open(Startups.csv)
if err != nil {
log.Fatal(err)
}
defer file.Close()
Next, create the dataframe:
startupDataframe := dataframe.ReadCSV(Startups.csv)
//print out result
fmt.Println(startupDataframe)
Once the data is organized as a dataframe, other manipulative actions like filtering can follow suit:
filter := dataframe.F{
category: "Country"
equals: "=="
subCat: "United States"
}
To filter only rows where United States is the subcategory:
usDF := startupDataframe.Filter(filter)
if usDF.Err != nil{
log.Fatal(usDF.Err)
}
To strip and access only a few columns in the filtered dataframe:
usDF := startupDataframe.Filter(filter).Select([]string{"Company", "Valuation", "Industry"})
To repeat the above and print out only data from the first 100 companies:
usDF := startupDataframe.Filter(filter).Select([]string{"Company", "Valuation", "Industry"}).Subset([]int{:100})
Asides these operations, the dataframe package makes it possible for the Go ML Engineer to merge datasets, output to other formats, and even process JSON data. For more information about this package, visit the auto-generated GoDocs.
In the next article on this series, the Go ML Engineer will learn how to work with JSON in Go; a more suitable data container than CSV files. Persisting with an SQL database may also be treated.